The Paper is Coming from Inside the House!
That is, a study co-authored by a science journalist
Hi there! This is TITLE-ABS-KEY(“science journalism“), a newsletter about science journalism research. In the previous issue, I did my best to avoid just writing SCIENCE JOURNALISM IS AWESOME in all caps all the way up to Substack’s email length limit.
Today, I’m keeping up with the Kardashians scientific publishing trends and reading a preprint instead of a properly (I sure hope) peer reviewed and published paper. And it’s no random preprint I must say.

Today’s paper: Bottesini, Julia G., et al. "How Do Science Journalists Evaluate Psychology Research?" (2022). DOI: 10.31234/osf.io/26kr3.
Why this paper: I am not at all ashamed to admit to some light to moderate fangirling over one of the co-authors, Christie Aschwanden.
Abstract: What information do science journalists use when evaluating psychology findings? We examined this in a preregistered, controlled experiment by manipulating four factors in descriptions of fictitious behavioral psychology studies: (1) the study’s sample size, (2) the representativeness of the study’s sample, (3) the p-value associated with the finding, and (4) institutional prestige of the researcher who conducted the study. We investigated the effects of these manipulations on real journalists’ perceptions of each study’s trustworthiness and newsworthiness. Sample size was the only factor that had a robust influence on journalists’ ratings of how trustworthy and newsworthy a finding was, with larger sample sizes leading to an increase of about two thirds of one point on a 7-point scale. Due to high precision, we can confidently rule out any practically meaningful effect in this controlled setting of sample representativeness, the p-value, and most surprisingly, university prestige. Exploratory analyses suggest that other types of prestige might be more important (i.e., journal prestige), and that study design (experimental vs. correlational) may also impact trustworthiness and newsworthiness.
When I saw this preprint, I knew I would use it for the newsletter because, if we’re sticking to the overarching analogy for this project, this is as if a meerkat could read a study of meerkats — but co-authored by another, wildly more successful meerkat.
Christie Aschwanden is a former FiveThirtyEight science journalist, she’s written a book about the science of sport, she used to be a professional ski racer, and now she leads sold-out workshops from her winery and farm in western Colorado. In the preprint, she listed the Council for the Advancement of Science Writing as her affiliation because, naturally, she is the VP of that renowned organization.
Okay, now that we’ve established my fangirl credentials, let’s dig into that abstract. You may know that the replication crisis in psychology has spawned many a journalistic article (I have one, as does Christie; not linking to mine here as it’s in Russian). One of the proposed solutions to the crisis is preregistration, an approach that requires the study authors to agree to and publish a protocol before they even start collecting the data. So, naturally, I am delighted to see that a study of journalists evaluating psych research is also preregistered. It’s also a controlled experiment, which allows the authors to make strong claims. 10/10 on practicing what you preach.
Science journalists play an important role in the scientific ecosystem. They are the primary external watchdogs that can monitor scientists and scientific institutions for problematic practices and call out dubious claims without much fear of harming their career prospects. Not gonna lie, I feel seen in this intro.
The authors posit that if journalists act as a slice in the whole Swiss cheese model of academic risk reduction, we need to know how they make their reporting decisions. It’s understandably hard to unpack those holistic decisions (often based on gut feeling), but you can also use some characteristics of studies that are much easier to operationalize than whether it’s cool or not. And of course, if you don’t just rely on self-reported unpacking, you can avoid interfering with that intricate decision making process or getting stuck with artificial, reverse engineered reasoning, when journalists have to come up with justifications for decisions made on a hunch. Also, much less interview transcribing.
The next section of the paper is titled The Importance of Science Journalists, and even though I completely agree with all points made in this section, I am going to skip it for this newsletter because, frankly, I got high blood sugar just by reading something so complimentary to my craft. I simply can’t handle agreeing with it line by line. I am going to quote one point, though, for the express purpose of showing you my favorite graph ever.
When it becomes clear that this [an impression that all published findings are equally solid] is not warranted — if coffee cures cancer one week but causes it the next — this can erode public trust in science, and at the extremes, facilitate the types of science denialism we see, for example, toward climate change research.
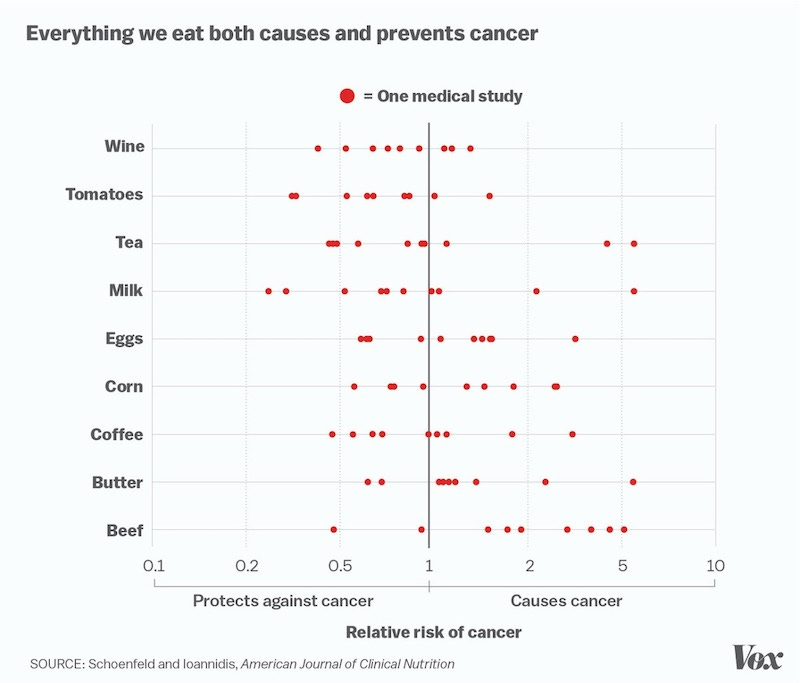
Alright, so let’s jump to the experiment. As a first step to understanding the factors that influence science journalists’ decision-making, we investigated how science journalists evaluate research findings in psychology. Specifically, we invented findings similar to those that might arise in the field of social and personality psychology (our area of expertise), and experimentally manipulated four features of these research studies to investigate how these features affect science journalists’ perceptions of the research. <…> Our aim was to examine the causal effects of these factors on our dependent variables: journalists’ perceptions of the trustworthiness and newsworthiness of the research presented.
I was really curious about the invented findings, which were presented to participants as vignettes, i.e. short and neutral descriptions of study results. The two non-journalist co-authors wrote 25 vignettes and calibrated them to be moderately interesting and plausible. But then the third journalist co-author reported three vignettes to be too implausible, so they went with 22.
Because I had to know what was too implausible for Christie Aschwanden, I went through the study materials to find the three vignettes that had been dropped, comparing documents in the OSF page based on my keywords for each one. And reader, at first I couldn’t do it, and it was driving me a bit mad.
But then I realized that the list of original vignettes in the pretest folder was missing three numbered paragraphs. Two takeaways: first, it’s really easy to confuse your (tired) reader when your list is long enough; second, this does not exactly look like good preregistration :(
But anyway, U.S.-based science journalists took part in the experiment (186 in total, recruited through the professional networks of Christie Aschwanden directly and by snowball sampling), and the four parameters chosen by the authors are as follows:
sample size (number of participants in the study),
sample representativeness (whether the participants in the study were from a convenience sample or a more representative sample),
the statistical significance level of the result (just barely statistically significant or well below the significance threshold),
and the prestige of the researchers’ university (not immediately clear how this was defined and assessed — the survey documentation just has a list of more and less prestigious universities. This becomes one of the limitations of this study).
Okay, I loved the convenience sample euphemism there (it’s an open secret that a lot of these social and personality psychology studies are done on undergrads or graduate students, which is, erm, not terribly representative). But isn’t your own sample ultimately also a convenience one?… Although, and I am getting ahead of myself, turns out this factor is irrelevant to journalists (who similarly would not care about this particular sample of themselves.)
In the experiment, each participant saw eight random vignettes with manipulated study parameters and had to agree or disagree with statements such as “this study is trustworthy“ or “this finding is newsworthy.“ They were then asked several open-ended questions on how they assess the quality of a study, debriefed on manipulated variables and asked some demographics questions.
Of the 181 participants in the final sample, 76.8% were women, and about a quarter (26.5%) said they regularly cover psychology. They also overwhelmingly worked for online news organizations (92.3%), and 48.1% reported having a journalism degree. I only have anecdotal evidence here, but a sample like this would probably not be representative in a Russian experimental setting.
Trustworthiness and newsworthiness were highly correlated, as to be expected, in part because, at least for psychology, this correlation is a socially desirable response from a journalist (even when no one is looking it would be hard to claim that something you don’t really trust is worth reporting on, and vice versa). And indeed, the team is concerned that journalists being aware they were being studied may have affected the outcomes.
When participants described their decision making, they largely validated the choices made by the study team, in that most talked about the very variables chosen for the experiment. The predictably weak link was the university prestige, which did not add to either validity or newsworthiness (prestige may mean something after all, but for journals and not research orgs — this is coming from the open-ended answers as well.)

Yet there was at least one more factor mentioned in open-ended responses: study design, as authors had naturally chosen either correlational or experimental design for the made up studies in the vignettes — and participants picked up on that and rated vignettes with an experimental design as being higher on trustworthiness and newsworthiness.
When asked what characteristics of a study they considered when evaluating its trustworthiness, participants often mentioned the prestige of the journal where it was published or the fact that it had been peer reviewed. <…> Many participants mentioned that it was very important to talk to outside experts or researchers in the same field to get a better understanding of the finding and whether it could be trusted. Journalists also expressed that it was important to understand who funded the study, and whether the researchers or funders had any conflicts of interest. Finally, they indicated that making claims that were calibrated to the evidence was also important and expressed misgivings about studies for which the conclusions don’t follow from the evidence.
So, as we’ve seen, only sample size is king (queen? gender-neutral ruler?). While we did not preregister any predictions, we admit to being surprised by the finding that journalists’ evaluations of research were not affected by the prestige of the authors’ institutions. We expected journalists to perceive research conducted at more prestigious institutions to be both more trustworthy and more newsworthy. Our results suggest this stereotype — that science journalists are influenced by flashy university names — is wrong, at least in contexts similar to this experiment and with journalists similar to those in our sample.
I think that, with the p-value assumption in particular, the team has out-nerded itself because participants readily admitted they used p to see whether the result is significant at all but did not then discriminate within the statistically significant ones.
Limitations of the study, naturally, include a dramatic oversimplification of the evaluation process: the vignettes were basically summaries of press releases, and the only decision I’m making based on those is maybe whether to download and read the paper.
Then there’s the Aschwanden effect: that science journalists in the same professional network as Aschwanden will be more familiar with issues related to the replication crisis in psychology and subsequent methodological reform, a topic Aschwanden has covered extensively in her work. Therefore, we are not confident that the results obtained here can be generalized to all U.S.-based science journalists. Instead, our conclusions should be circumscribed to U.S.-based science journalists who are at least somewhat familiar with the statistical and replication challenges facing science.

The authors go on to explore the not so encouraging implications of their findings, basically saying this can all be bad news. Attention to sample size may come at the expense of other important factors; lack of interest in sample representativeness perpetuates the undergraduate students status quo; p-hacking is not punished; prestige-related cues such as journal prestige as shorthand for quality is harmful. Ugh, I thought this would go better.
Well, it may actually go better through qualitative and observational studies which would then inform the design of better experimental research — or even intervention studies where, for instance, journalists are taught about p-hacking and being suspicious of barely significant results.
More research on science journalism? This newsletter would definitely find that newsworthy.
That’s it! If you enjoyed this issue, let me know. If you also have opinions or would like to suggest a paper for me to read in one of the next issues, you can leave a comment or just respond to the email.
Cheers! 👩🔬